So the process of automating a pipeline to generate audio for practicing minimal pairs has been largely successful, in that I’m able to take a YouTube URL (or more precisely, multiple URLs) and from that generate data ready to be sent to a server for use in creating a website to help students practice listening to different speakers saying different minimal pairs.
Github Repository with source code
For a quick description of the process without needing to read the source code:
- I basically take raw audio and transcripts from a YouTube video
- get all the minimal pairs present in the transcript
- use a force-alignment process to get the time-stamp of every word in the transcript/audio pair
- use the minimal pair list to selectively grab just the part of the audio that has the words I’m targeting, based on the time-stamp of that audio created in step 3.
- glue all the minimal pairs for a unique phoneme pair (eg, /I/ & /i/) into one longer audio track of multiple speakers saying the exact same minimal pair.
Here is a quick recap of the background to the idea.
First the bad news…
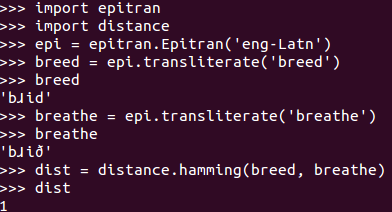
The process isn’t currently doing anything particularly smart in terms of deciding which minimal pairs are “better”, and so it ends up literally outputting everything with a “phonemic distance” of 1 (I’m using a Python implementation of Hamming Distance), and the quick description is that it finds any two IPA strings of the same length that have a difference in the same position and identifies that as a minimal pair.
…unfortunately, this results in a lot of pairs of words being identified as minimal pairs that aren’t necessarily productive for students to focus on. For example, /ə/ and /z/ are not usually something that students have a hard time with (the two words in the audio file are “coma” and “combs”). There’s also some weird results coming through that either aren’t rendering correctly in the browser, or just need to be filtered out because it’s bad data.

As shown by the screenshot from the chrome dev console below, data from 300~ videos resulted in a total of 603 unique phoneme pairs being identified by the system and eventually rendered through on the web app. That’s way too many, and definitely needs to be filtered.

Some of the audio files that get output are way too short (eg, only one speaker total saying a minimal pair), and the audio snippets that get pulled out are also way too short (eg, a speaker saying “good”, but only lasting about .2 seconds, which is too short to actually make out what word they’re saying).
Lastly, the source code itself needs massive refactoring and cleaning up, since I’ve gotten it to the point where it’s essentially a working pipeline, but that involved numerous iterative steps without necessarily knowing what direction, architecturally, I was headed in.
TL;DR – can be made faster and more concise.
What are the current successes?
I’ve demonstrated that the process works with a fair amount of data (the 300 videos took a while to process, and I would estimate that one entire run-through of that on a very basic/cheap cloud server took about 2.5 days, and resulted in around 800 MB of total audio assets).
In some cases I’m seeing very encouraging results, with a high number of different minimal pairs per phoneme pair, with a fair amount of sample audio for a given minimal pair (eg, 23 minutes of different speakers saying both “as” and “is”, shown below).

I’ve proven the process is scalable to X number of videos (given enough time), and so although filtering out some of the less intelligible audio would initially leave us with less data to present in the actual web app, increasing the number of videos processed will hopefully allow us to find enough high quality audio that this effect is mostly (if not completely) offset.
By only appending the <audio> tags to the browser when that particular audio track is requested, the browser only downloads the specific audio when the user requests it, so bandwidth is limited only to what’s absolutely necessary.
Work to be done in the processing
The most basic thing, at least for now, is just to focus on the vowel-based minimal pairs, since they will occur almost invariably in the middle of the words, and therefore have a much higher chance of being heard in short audio snippets. That’s more or less an easy filter setting based on the meta-data I’m passing through from the server.
I need to both improve the filtering and the quality of the audio that makes it to the user. I came across one academic paper (don’t remember the source) that suggested using Praat scripts to lengthen just the vowels of the minimal pairs, and this is something I might try.
I’ve already attempted to slow down some of the audio, so that it’s hopefully a bit more intelligible, but this hasn’t been as effective as I would have liked.
Work to be done in the web app
I would also like to incorporate some sort of discrimination task, similar to the one in this very good paper where students have to select the sound that they heard, either in isolation or in the context of the original sentence (since we have the timings of every word in the audio, that wouldn’t be too hard to get).
There needs to be some way to search for a minimal pair to practice, either by one of the words involved, or by IPA. The design of the app also needs a massive overhaul, with better fonts/colors/buttons/menus/etc.
Sure, it doesn’t look great, and processing 2000+ videos will involve either scaling up to a bigger server or making the process distributed over multiple servers, which is either an increased money cost or a time cost (to figure out how to do it), respectively.
Unfortunately, none of that matters if I can’t get the audio sounding a bit better, so that’s my current area of focus.
Anyway, very happy to collaborate with anyone interested, and very open to any ideas on improving the audio quality (in my wildest dreams it would involve some sort of deep learning model that could “fill in” the phonemes around the vowels, but that’s a bit beyond me at the moment).

Thanks for update on this !!! Looking good 👍👍👍👍
LikeLike